Mise - Recipe Recommender
An NLP-powered recipe recommender that uses keyword matching and semantic transformers to match food vibes to recipes.
Do you ever crave something and not know the exact name of the dish you want? So you type the feeling and flavors of the dish, only to get vague results? If you cook at home, I already know your answer. Don't worry, it happens to all of us.
The reality is that people don't always search for food the way recipes are written. Sometimes they search by vibe: "warm and creamy dish," "that Spanish cold soup," "something spicy but vegetarian," "tomato and meat pasta", and many more.
Mise (short for "Mise en Place") is a recommender built to meet them there.
What Makes This Difficult?
Human communication is tricky; it takes a lot of context and shared experience to understand each other. If you tell me you want "that Japanese pork chop dish", I know what you mean because I've eaten it before.
But that intuition doesn't translate to how a machine thinks. A machine doesn't understand the sentence the way you do; it has no memory of eating katsudon or tonkatsu to draw upon. What it can do is convert text to numbers and compare the numbers to find that relation. There are fundamentally two ways to do this.
The first way is literal; the machine treats your sentence as a bunch of words and looks for those words in recipes. The downside is it only matches words, not meaning. It can find pork in a recipe but it can't understand "pork chop" and "tonkatsu" are related.
The second way is meaning; the machine learns from a tremendous amount of human text to be able to convert your sentence into a vector and decode the meaning from it. Here, "pork chop" and "tonkatsu" would be close to each other in number space because the model learned from context they are related, even if there are no matching words.
The downside here is that it can be imprecise on the specifics. Because embeddings match on meaning, sometimes you can get results that are say, in the right neighborhood, rather than what you actually wanted. This would be like typing chicken biryani and getting results for lamb biryani, chicken paella, or just any generic rice dish because they're all semantically similar. There is no priority given to keyword matches, and it will settle for being vaguely right.
So to actually solve our problem, neither method is enough on their own. We need a system that combines the best of both.
The Hybrid Approach
Since neither method accomplishes what we need on their own, the best option is to use both together to cover for each other's weaknesses.
At its core, Mise scores every search with two signals. A keyword ranker BM25 ensures exact searches will be recognized, while the MiniLM sentence transformer handles synonyms, vibe searches, and descriptions of dishes that share no wording with the recipe name. This is the heart of the recommender, and both run on every search.
The two are blended into a single ranking:
| Signal | Weight | What it captures |
|---|---|---|
| Semantic (MiniLM) | 0.45 | meaning, vibe, synonyms |
| Keyword (BM25) | 0.15 | exact word matches |
Semantic carries the most weight because the primary point of Mise is to capture a person's intent behind their recipe search. Keyword matching is the smaller, but still meaningful signal that keeps the system results precise while not drowning out the meaning.
On top of that, Mise has three optional filters to refine the ranking further: ingredients, cuisine, and category. These aren't part of the default search; they're here in case the user finds the current results too broad. When applied, each adds its own weighted signal to the score.
| Signal | Weight | What it captures |
|---|---|---|
| Ingredient | 0.20 | what's actually in the dish |
| Area | 0.10 | cuisine |
| Category | 0.10 | type of dish |
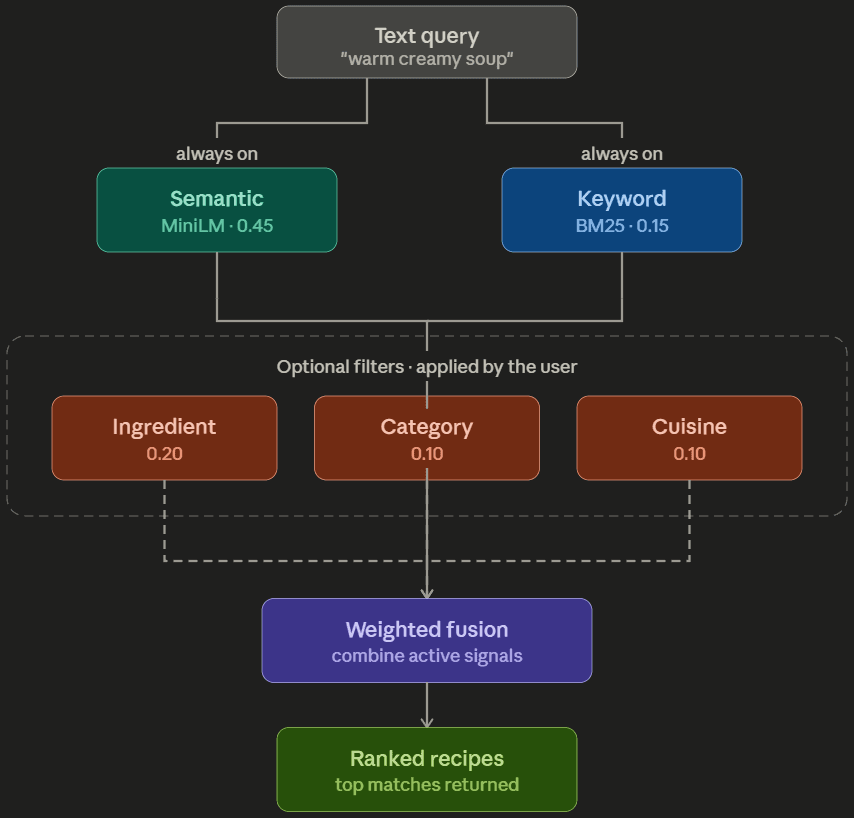
When no filters are selected, the system falls back to the pure semantic + keyword hybrid. The filter weights will drop out, and since every recipe is scored the same way, the ranking should remain correct. The idea is that the filters are there to make the results more precise, not muddy the core search.
Each signal is normalized to a 0–1 range before weighting, so a signal's weight reflects its real influence on the final score. The recipes themselves come from TheMealDB: roughly 600 dishes, each with a name, ingredients, category, cuisine, and instructions. At startup the system loads precomputed embeddings for every recipe, so a search is a fast comparison against vectors already in memory rather than an encode-on-the-fly. This makes for a smoother experience on the user's end.
From Notebook to Live App
I could've just built the recommender, got my results, and stopped there. But I wanted something more; I wanted something that I could actually share with people to interact with themselves. So I deployed it on the big live web.
Being the money miser I am, I tried to minimize my personal expenses to maintain the app. Mise runs as a FastAPI service on a single machine on Fly.io.
Initially I tried every free version, with RAM limits around 256MB, on deployment sites: Render, Fly.io, etc. That memory ceiling was the biggest issue I was running into. My first version used MPNet as the semantic model, which gave great embeddings. However, every attempt at deployment on Render and Fly.io was a failure due to memory out of bounds. When I checked into memory requirements, it was somewhere around 2.0GB. Increasing the RAM limits would've cost me almost $25/month to maintain an ML app I made for fun. That's more than a ad-free streaming account!
So I switched the semantic model from MPNet to MiniLM. MiniLM is a smaller, lighter sentence-transformer that took only a minor hit to retrieval quality while bringing memory use down enough to fit comfortably in 1024MB. This put me into a price range I was much more willing to spend, about $7/month.
To keep startup fast, the recipe embeddings are precomputed and baked directly into the deployment image. Instead of encoding all 600 recipes every time the machine starts, the app loads the finished vectors straight from the image, so cold starts are quick and a search is ready almost immediately.
The result is a live recommender, one that you, yes you the person reading this write-up, can click on the "Live Demo" button at the top and play around with the app in the exact same way I can in my local dev version.

Can you tell frogs are my favorite animal?
How I Knew It Actually Worked
Now it would've been very easy for me to trick myself into thinking it worked without testing. Run a few queries I know the answer to, see if the results make sense, and call it good. Sadly that's not how evaluation works; this is just confirmation bias with extra steps. So before I let myself believe it worked, I built an evaluation harness that hits my system with 4 different query types; good results could mean 4 different things depending on the person.
Type 1: Ingredient Queries
The first type is simple and straightforward: ingredient queries. "If I give a set of ingredients into the system, will it return recipes with said ingredients?" 50 recipes were sampled at a set seed, with each recipe's top 3 ingredients entered into both the search field and ingredient filter. Recall is what matters here, because I need to know whether the system actually brings up the desired instead of burying them. Mise scored 0.96 on Recall@10 with only 2 misses out of 50 and an MRR of 0.85, which means the right dishes both showed up and were near the first spot.
Type 2: Semantic and Category Matching
The second type is semantic and category matching: a query like "pasta recipe" should return things tagged as Pasta, and "American comfort food" should pull dishes from the United States. This is where the results got more honest. Precision@5 came in at a solid 0.84, so the top results it puts in front of you are usually the right kind of thing. But Recall@10 was only 0.44, meaning it surfaces a few good results while missing a lot of the relevant set. The reason is probably breadth; the hardest categories are the big, diverse ones. A region like the United States sprawls across burgers, pies, and casseroles that don't share much vocabulary, so a single query like "American comfort food" can land near some of them but can't possibly cover the whole group. This means the system is pretty good at "is what I showed you correct?", but weaker at "did I show you everything good?". It is a tradeoff, and verifying it is why it was tested in the first place.
Type 3: Exact Name Match
The third type is exact match, when someone already knows the dish name and just wants to find it. This is the bar a search box has to clear to ever be taken seriously. Thankfully Mise scored a perfect 1.00 on Precision@1 across 50 queries, zero misses. This means every exact-name query landed at rank 1. A sample size this large shows that this isn't lucky; the recipe's name is repeated three times in the text that BM25 indexes, so it's an overwhelmingly strong keyword signal. If you know what you want by name, you will get it first try at the top of your results.
Type 4: The Craving You Can't Name
The fourth type is the one this whole project was made for: human phrasing. This is the hardest test, because people don't describe food the way a database does. It's really where the "hybrid" in my system has to show up and perform.
Remember the craving I opened with, that Japanese pork chop dish? I typed that exact phrase into the live app, and this is what came back:
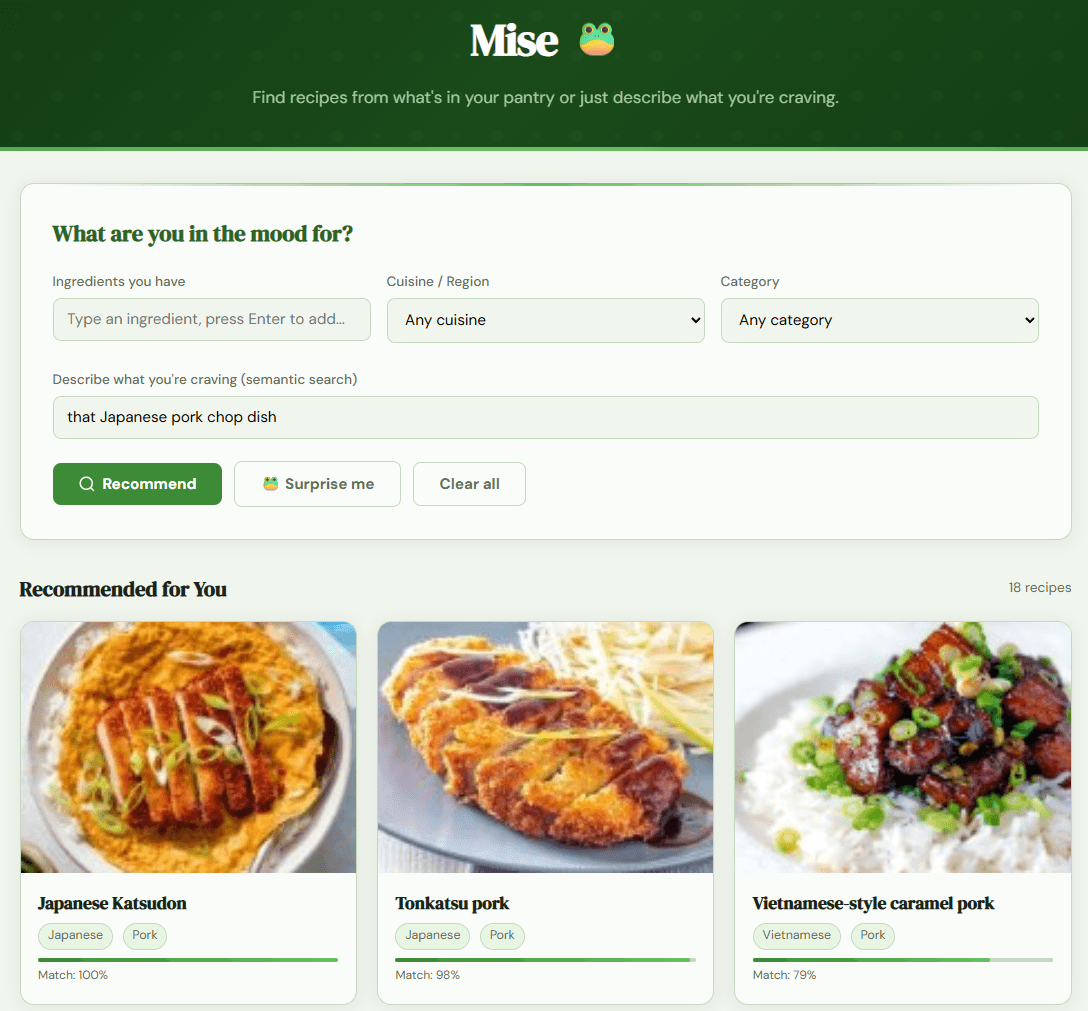
The two dishes I named by hand at the start of this writeup: Japanese Katsudon at the top with Tonkatsu right behind it. This is the hybrid working at its best. The word "pork" gave the keyword ranker somewhere to start, but "pork" alone matches dozens of recipes. What brought these two specific breaded-cutlet dishes above every other pork recipe in the set is the semantic model recognizing they are conceptually a "Japanese pork chop." Neither half does this alone. In fact, when I saw the sub-score comparison, semantics did most of the work and rated the two dishes almost dead even with Tonkatsu a tad higher, which is fair since tonkatsu is the more literal breaded pork cutlet. They were so close on meaning that the smaller keyword signal became the tiebreaker, and Katsudon's slightly stronger keyword match nudged it into first by less than a hundredth of a point. The hybrid approach landed on two answers that are exactly what I was craving.
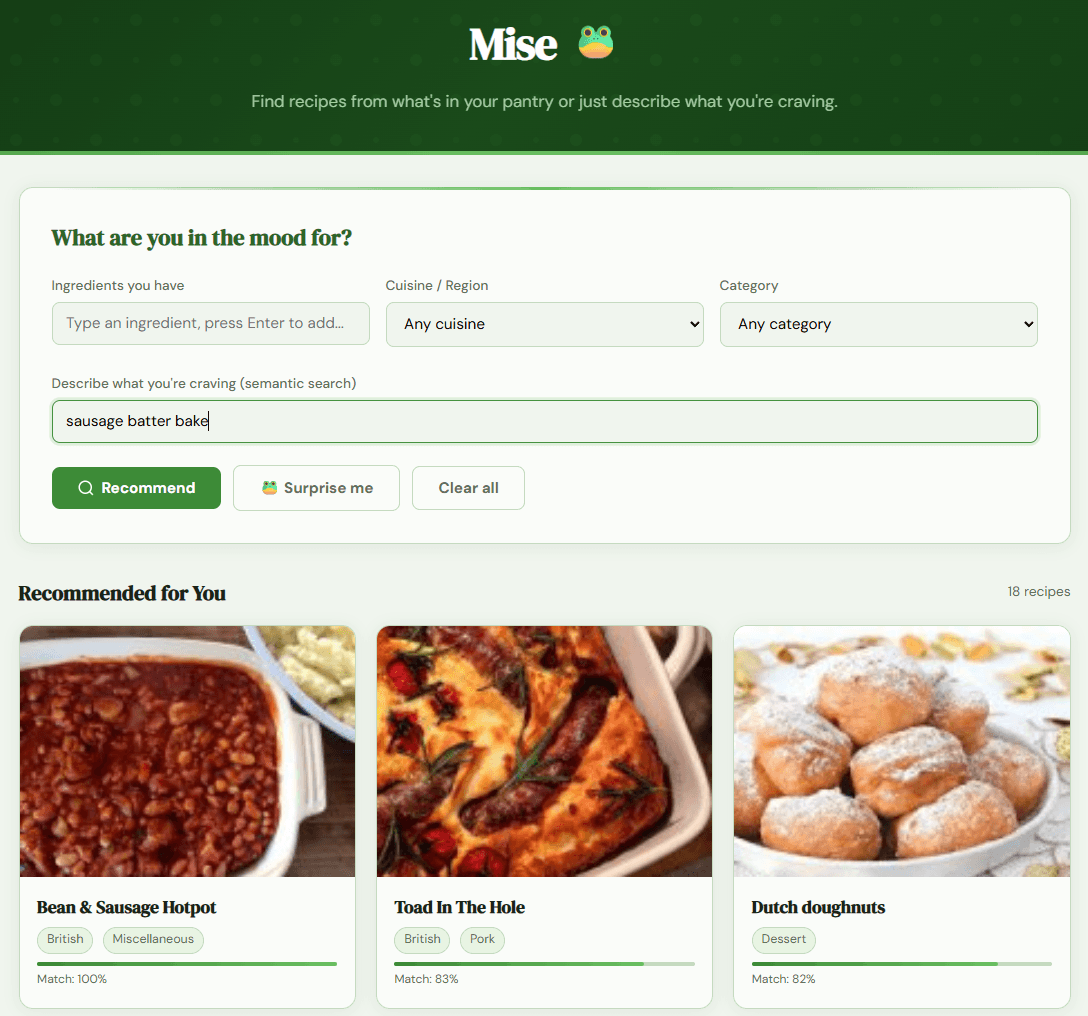
Another interesting case is "sausage batter bake," a plain description of components by someone who knows only what they ate. Mise returned Toad in the Hole, a dish whose name contains none of those words. Looking into the sub-scores shows why it worked: BM25 caught "sausage" and "batter" in the ingredients and instructions, while the semantic model, scoring higher than BM25 and contributing more than three times as much to the final rank, understood that this combination of ingredients adds up to that dish. Neither signal would've gotten there on its own. The keyword match alone would rank it as just another recipe mentioning sausage; the semantic match enables the leap from a bag of ingredients to the specific named thing. This is the hybrid doing exactly what I built it to do. I checked it live in the deployed app too, and it came back as the second result.
This evaluation set contained 10 queries overall, measured with MRR, and scored 0.55. This works out to the desired dish landing around rank 2 on average. Not perfect, but does show promise; describe a vibe, and the thing you meant usually doesn't need you to scroll.
So evaluation is done for now with four queries and an interesting pattern across them. The scores are highest where the query and the recipe share words, and they soften right at the point where a person means something they don't explicitly say. That seam between matching words and matching meaning is the whole story of this project, so looking into that is what the next section is all about.
What I Learned From Testing
The most expensive part of this system was the semantic model. It's the component that ate the majority of the RAM, forced me to swap MPNet to MiniLM, and turned a simple deploy into a problem-solving session with a budget negotiation. So the fair question after all that is whether it earned its place, and I think the fourth query type is where it answers for itself. It did, just not in the way I first assumed.
I went in expecting the embeddings to do things keywords flat out couldn't, but the truth told a different story when I pulled the scores apart. On "that Japanese pork chop dish," the keyword ranker did fire, because "pork" really is in those recipes. But "pork" alone matches dozens of dishes, and it was the semantic model carrying the larger share of the score that sorted the two breaded cutlets above the rest of the bunch. Same story with the "sausage batter bake": keywords caught "sausage" and "batter", but semantics supplied the actual leap from listed ingredients to "Toad in the Hole". So the embeddings didn't replace keyword matching, they did something subtler and just as valuable. They took the rough pile of word matches and ranked the desired answer to the top. That is the part I wholeheartedly defend.
However, where it breaks is the mirror image of where it shines. The same model that ranks "sausage batter bake" to the right dish has no way to honor a specific property the user actually cares about. Take a plain craving like "warm creamy soup". Two of the three genuinely creamy soups in the dataset, "creamy tomato soup" and "fiskesuppe", are the top two results. This is great. But the third one, "clam chowder", never appears at all. The recipe text doesn't share any words with the query. The system isn't reasoning about creaminess; it's matching the words that describe it, and a creamy soup that fails to use those words is invisible to it. It can't tell that "creamy" is a requirement and "soup" is just the category.
Push that one step further into a query like "creamy without dairy" and it falls apart completely, because now the user needs the system to exclude something and the system has no concept of exclusion. It reads "dairy" as just another word to drift toward, so it gladly hands back dishes full of the exact thing you ruled out. There is no "not" in a similarity score.
This is where the human-machine gap I meantioned in the start is showing up in the results. A person saying "creamy without dairy" is drawing a hard line. The system only sees a bunch of words and asks "which recipes feel near these"? That isn't a weight I can tune my way out of, I tried. No amount of nudging semantic up or keyword down teaches a similarity score what "without" means. That is unfortunately a structural limitation. Similarity retrieval is built to answer "what is this like" when some questions are really "what must this include and what must it never have", which is a different question wearing the same clothes.
Knowing that tells me what the fix actually is and what it isn't. It isn't a better embedding or a smarter weighting; it's an entirely new mechanism sitting alongside similarity, one that can take a requirement like "no dairy" and treat it as a filter that removes violators outright, rather than hoping the system stumbles upon the right answer. Similarity is the right tool for "what's this like". It's the wrong tool for "but not that" and the finding here is that I built the first and discovered by testing where I'll need the second.
What's Next for Mise
Every limitation in the last section points at a specific next step, so here's where Mise goes from here.
The obvious one is the constraint problem. As it stands, the system has no way to honor a "without", and no amount of reweighting fixes that. The fix is a second mechanism that runs alongside the similarity score: a hard filter that reads a requirement like "no dairy" and removes the recipes that violate it outright. Similarity would still do what it's good at, deciding what a query is like, and the filter would enforce the lines the user actually drew. This is probably the single change that would close the widest gap between what Mise understands and what a person means.
The second is an honest follow-up on a choice I already made. I picked BM25 over plain TF-IDF for two specific reasons: term-frequency saturation so a recipe repeating "chicken" twenty times doesn't overwhelm one that mentions it three times, and document-length normalization so a short focused recipe isn't penalized against a long rambling one. Those are good reasons on paper, but the rigorous move is to prove it rather than assert it. An ablation, running the same evaluation harness with TF-IDF swapped in for BM25, would tell me whether that choice was meaningful or it just sounded right. After a whole writeup about not trusting my own assumptions, leaving this one untested would be a little hypocritical (although I do think I'm right here).
The third is narrower but it's the one my results most clearly asked for. Type 2 showed strong precision and weak recall on broad categories, the system surfaces good results but misses much of the other relevant ones. Part of that goes back to how the keyword scores are normalized per query rather than across the whole system, which makes scores harder to compare between searches. Moving to a system-wide normalization would make the signals more consistent from one query to the next, and it's the most direct lever I have on that recall gap.
None of these are extraordinary or out-of-this-world. Honestly most of them are mundane. But they're the specific, unglamorous next steps that come up because of me actually measuring the thing instead of assuming it works. This is the whole reason I built the evaluation harness in the first place.
Mise started as a way to find a dish I couldn't name, but it ended up being a far better lesson in the gap between matching words and understanding meaning, and how much of that gap you only ever see by testing for it.